基础知识 - 代码随想录(持续更新ing)

基础知识 - 代码随想录(持续更新ing)
Mr.L本篇是数组与链表的入门综述,目标是建立「存储结构 → 操作代价 → 场景选择」的统一认知。
- 先看数组:连续内存、查询快、增删慢。
- 再看链表:离散内存、增删快、查询慢。
- 最后对比:根据业务特点选择结构。
- 数组 定义、性质、局限与二维连续存储。
- 链表 类型、存储方式、定义与增删操作。
- 对比 频繁查询优先数组,频繁增删优先链表。
数组
定义: 数组是存放在连续内存空间上的相同类型数据的集合
性质:
- 数组下标都是从0开始的;
- 数组内存空间的地址是连续的;
- 数组的元素不能删除,只能覆盖。
局限: 因为数组在内存空间的地址是连续的,所以我们在删除或者增添元素的时候,就难免要移动其他元素的地址;
注:使用C++,要注意vector 和 array的区别,vector的底层实现是array,严格来讲vector是容器,不是数组
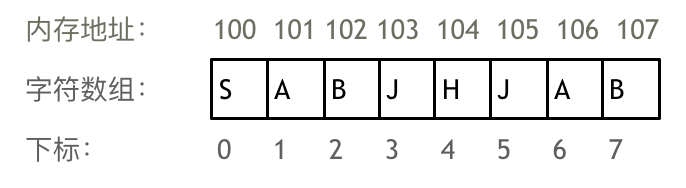
不同编程语言的内存管理是不一样的,以C++为例,在C++中二维数组是连续分布的。
1 |
|
测试地址为:
1 | 0x7ffee4065820 0x7ffee4065824 0x7ffee4065828 |
链表
定义: 一种通过指针串联在一起的线性结构,每一个节点由两部分组成,一个是数据域一个是指针域(存放指向下一个节点的指针),最后一个节点的指针域指向null(空指针的意思)。链表的入口节点称为链表的头结点也就是head。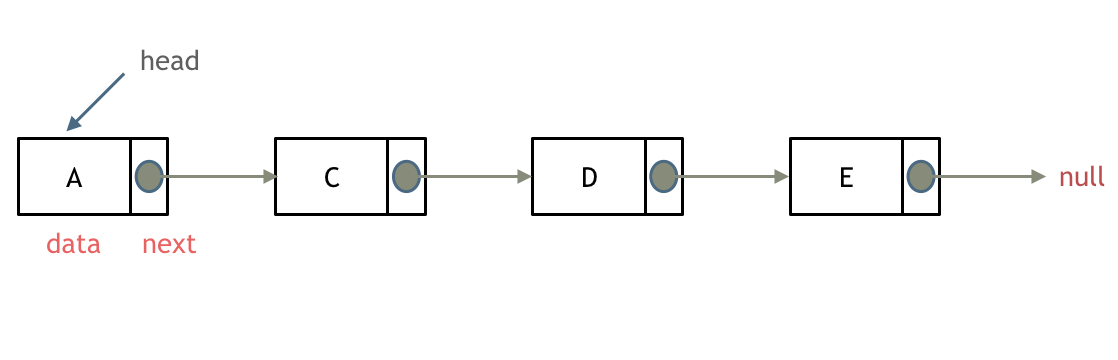
链表的类型:
- 单链表: 上述提及的就是单链表;单链表中的指针域只能指向节点的下一个节点。
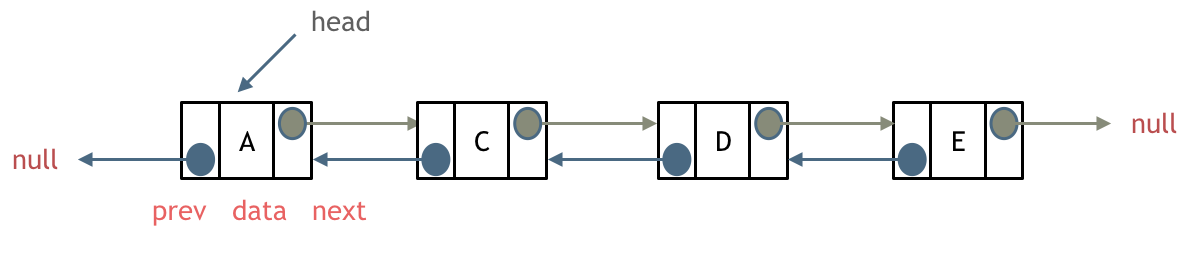
- 双链表: 每一个节点有两个指针域,一个指向下一个节点,一个指向上一个节点。双链表既可以向前查询也可以向后查询。
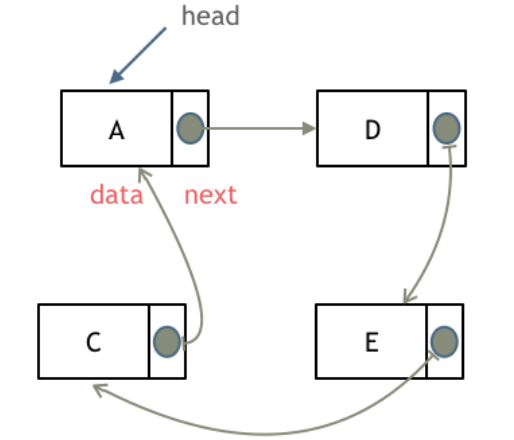
循环链表: 链表首尾相连,可以用来解决约瑟夫环问题。
链表的存储方式
数组是在内存中是连续分布的,但是链表在内存中可不是连续分布的。
链表是通过指针域的指针链接在内存中各个节点。
所以链表中的节点在内存中不是连续分布的 ,而是散乱分布在内存中的某地址上,分配机制取决于操作系统的内存管理。
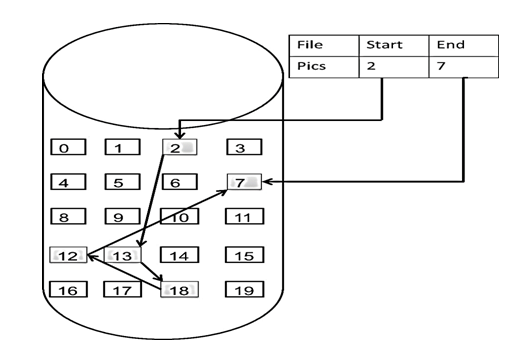
链表的定义
1 | // 单链表 |
不定义构造函数也可以,C++默认生成一个构造函数,但不会初始化成员变量,不能直接给变量赋值!如:
自己定义构造函数初始化节点:
1
ListNode* head = new ListNode(5);
使用C++默认构造函数初始化节点:
1
2ListNode* head = new ListNode();
head->val = 5;
链表的操作
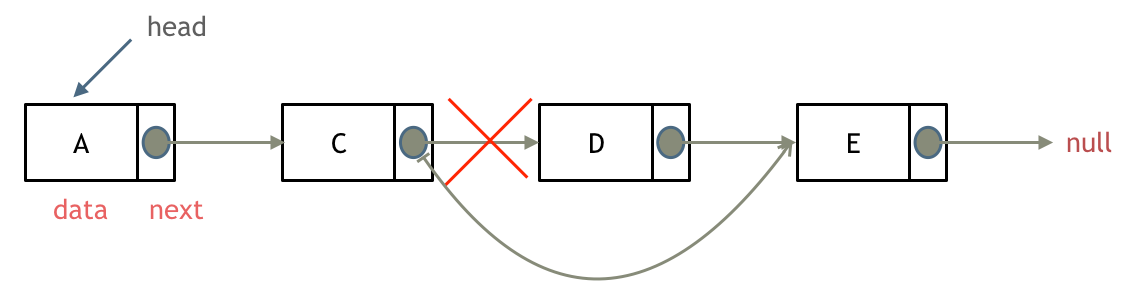
删除节点
只要将C节点的next指针 指向E节点就可以了。
D节点依然存留在内存里,在C++里最好是再手动释放这个D节点(delete node),释放这块内存。
其他语言例如Java、Python,有自己的内存回收机制,就不用自己手动释放了。
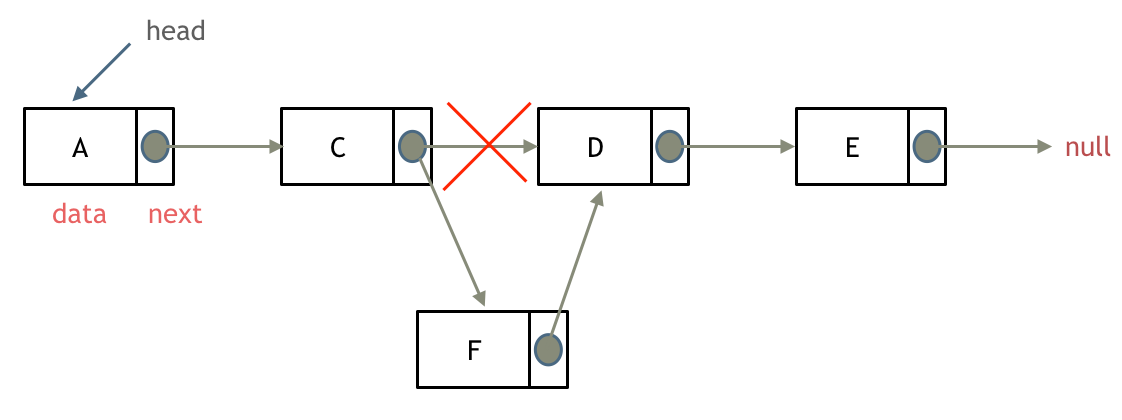
添加节点
可以看出链表的增添和删除都是O(1)操作,也不会影响到其他节点。
但是要注意,要是删除第五个节点,需要从头节点查找到第四个节点通过next指针进行删除操作,查找的时间复杂度是O(n)。
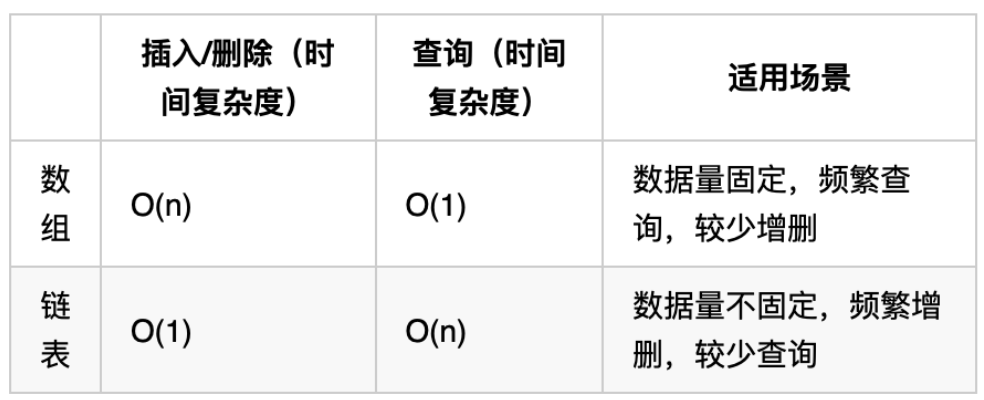
性能分析
- 数组定义时,长度固定,如果想改动数组长度,需要重新定义一个新的数组。适合数据量固定,频繁查询,较少增删 的场景。
- 链表长度可以不固定,且可以动态增删, 适合数据量不固定,频繁增删,较少查询 的场景。
哈希表
我们现在想要查询一个名字是否在这所学校里。
如果要枚举的话时间复杂度是O(n),但如果使用哈希表的话, 只需要O(1)就可以做到。
哈希表是根据 key 值而直接进行访问的数据结构,哈希表常用来快速判断一个元素是否出现集合里
哈希函数
哈希函数,通过 hashCode 把名字转化为数值,一般 hashcode 是通过特定编码方式,将其他数据格式转化为不同的数值,从而把学生名字映射为哈希表上的索引数字。

为保证映射出来的索引数值都落在哈希表上,当 hashCode 得到的数值大于哈希表的大小,我们会对数值做一个取模的操作,这样我们就保证了学生姓名一定可以映射到哈希表上了。
哈希碰撞
但如果学生的数量大于哈希表的大小又该怎么办? 无法避免不同学生的名字同时映射到哈希表同一个索引下标的位置,即哈希碰撞。
如图所示,小李和小王都映射到了索引下标 1 的位置,一般哈希碰撞有两种解决方法, 拉链法和线性探测法。

拉链法
假如小李和小王在索引 1 的位置发生了冲突,发生冲突的元素都被存储在链表中,这样我们就可以通过索引找到小李和小王
拉链法需要选择适当的哈希表的大小,这样既不会因为数组空值而浪费大量内存,也不会因为链表太长而在查找上浪费太多时间。

线性探测法
线性探测法依靠哈希表中的空位来解决碰撞问题,需要保证 tableSize 大于 dataSize。
例如冲突的位置,放了小李,那么就向下找一个空位放置小王的信息,如图所示:

常见的哈希表结构
当使用哈希法来解决问题的时候,一般会选择如下三种数据结构。
- 数组
- set (集合)
- map(映射)
这里数组就没啥可说的了,来看一下set。
在C++中,set 和 map 分别提供以下三种数据结构,其底层实现以及优劣如下表所示:
| 集合 | 底层实现 | 是否有序 | 数值是否可以重复 | 能否更改数值 | 查询效率 | 增删效率 |
|---|---|---|---|---|---|---|
| std::set | 红黑树 | 有序 | 否 | 否 | O(log n) | O(log n) |
| std::multiset | 红黑树 | 有序 | 是 | 否 | O(logn) | O(logn) |
| std::unordered_set | 哈希表 | 无序 | 否 | 否 | O(1) | O(1) |
std::unordered_set 底层实现为哈希表,std::set 和 std::multiset 的底层实现是红黑树,红黑树是一种平衡二叉搜索树,所以key值是有序的,但key不可以修改,改动key值会导致整棵树的错乱,所以只能删除和增加。
当我们要使用集合来解决哈希问题的时候,优先使用unordered_set,因为它的查询和增删效率是最优的,如果需要集合是有序的,那么就用set,如果要求不仅有序还要有重复数据的话,那么就用multiset。
| 映射 | 底层实现 | 是否有序 | 数值是否可以重复 | 能否更改数值 | 查询效率 | 增删效率 |
|---|---|---|---|---|---|---|
| std::map | 红黑树 | key有序 | key不可重复 | key不可修改 | O(logn) | O(logn) |
| std::multimap | 红黑树 | key有序 | key可重复 | key不可修改 | O(log n) | O(log n) |
| std::unordered_map | 哈希表 | key无序 | key不可重复 | key不可修改 | O(1) | O(1) |
std::unordered_map 底层实现为哈希表,std::map 和std::multimap 的底层实现是红黑树。同理,std::map 和std::multimap 的key也是有序的。
map 是一个key value 的数据结构,map中,对key是有限制,对value没有限制的,因为key的存储方式使用红黑树实现的。
虽然std::set和std::multiset 的底层实现基于红黑树而非哈希表,它们通过红黑树来索引和存储数据。不过使用方式还是哈希法的使用方式,即依靠键(key)来访问值(value)。所以使用这些数据结构来解决映射问题的方法,我们依然称之为哈希法。std::map也是一样的道理。






